【MySQL实战】数据库常用知识点/技术收录(不断更新中)
本文将收集在实际项目开发中,会使用到的MySQL一些技术及知识点。
一、命名规范
MySQL 基本命名规范使用有意义的英文词汇,词汇中间以下划线分隔。(尽量不要用拼音)推荐使用英文字母,数字,下划线,并以英文字母开头。且所有命名推荐只使用小写字母。并需要避免使用用ORACLE、MySQL的保留字,如desc,关键字如index。
1、库名
以项目英文简短命名,如:baike、weibo、blog等
- 临时库以tmp为后缀。 blog_tmp
- 备份库以bak+日期为后缀blog_bak_20220512
2、表名
统一表前缀,以下划线隔开单词,表名以复数形势。同一个模块的表尽可能使用相同的前缀,表名称尽可能表达含义。所有日志表均以 log_ 开头。
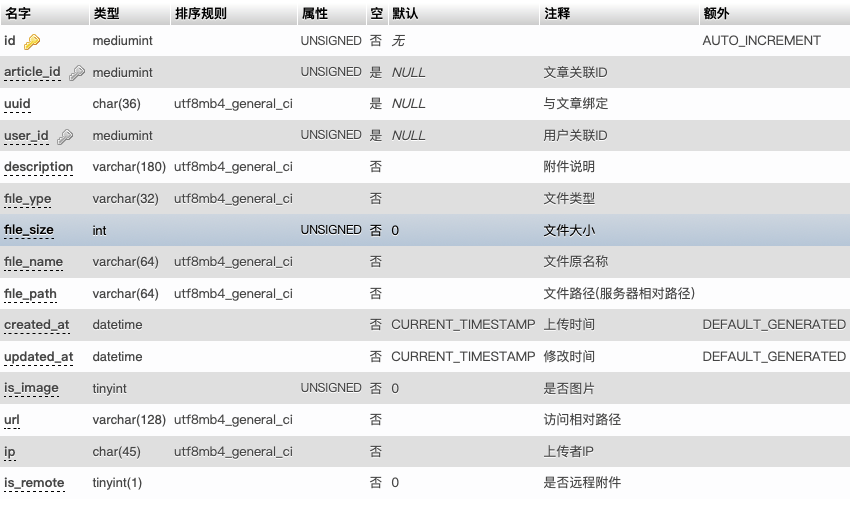
例如:本站的附件表:neter_articles_attachments(项目名_文章模块_附件表)。
3、字段名
- 表达其实际含义的英文单词或简写。布尔意义的字段以“is_”作为前缀,后接动词过去分词。
- 各表之间相同意义的字段应同名。各表之间相同意义的字段,以去掉模块前缀的表名_字段名命名。
- 外键字段用表名_字段名表示其关联关系。
- 表的主键一般都约定成为id,自增类型,是别的表的外键均使用xxx_id的方式来表明。
4、索引命名
- 非唯一索引必须按照“idx_字段名称_字段名称[_字段名]”进行命名
- 唯一索引必须按照“uniq_字段名称_字段名称[_字段名]”进行命名
二、存储
1、字符集(推荐uft8mb4)
大多数情况下,我们通常只使用下面几种字符集存储数据,但目前只推荐uft8mb4字符集。
| 编码 | 存储大小 | 介绍 |
|---|---|---|
| utf8 | 3字节 | 多语言的字符,早期使用较多,目前已被下面的uft8mb4替代。 |
| utf8mb4 | 4字节 | 与utf8不同的是,单个存储占用4字节,这意味着是表里面可以存emoji表情包。 |
| gbk | 2字节 | 简体中文,早期存储较贵(虚拟主机空间只有100mb),所以比较流行。现在推荐使用上面的mb4 |
| big5 | 2字节 | 同gkb,只是存放繁体中文,不再推荐使用。 |
2、常用存储引擎(推荐InnoDB)
MEMORY 内存表:经常访问、只读或很少更新的非关键数据(缓存、临时信息等),但不支持text、BLOB等数据类型,现在使用得不多了,InnoDB及其缓冲池内存区域提供了一种通用和耐用的方式来将大多数或所有数据保存在内存中,NDBCLUSTER为巨大的分布式数据集提供了快速的键值查找。
InnoDB 通用存储引擎:平衡了高可靠性和高性能。在MySQL 8.0中,InnoDB是默认的MySQL存储引擎,InnoDB将用户数据存储在集群索引中,以减少基于主键的常见查询的I/O。为了保持数据完整性,InnoDB还支持FOREIGN KEY引用完整性约束。
MyISAM : 基于ISAM存储引擎的扩展,做为曾经的王者,现在基本被上面的InnoDB替代,但MyISAM有一个超好用的方式,复制data目录下数据库名的文件夹就可以备份数据。超方便的,通常用于只读或主要读工作负载。而InnoDB则需要: http://www.55mx.com/server/38.html 这样的方式备份。
三、常用字段属性
1、数字类:
MySQL支持SQL标准整数类型INTEGER(或INT)和SMALLINT。作为标准的扩展,MySQL还支持整数类型TINYINT、MEDIUMINT和BIGINT。下表显示了每种整数类型的所需存储空间和范围。
MySQL支持的整数类型所需的存储和范围:
| 类型 | 存储(字节) | (有符号)最小值 | (无符号)最小值 | (有符号)最大值 | (无符号)最大值 |
|---|---|---|---|---|---|
TINYINT |
1 | -128 |
0 |
127 |
255 |
SMALLINT |
2 | -32768 |
0 |
32767 |
65,535 |
MEDIUMINT |
3 | -8388608 |
0 |
8388607 |
16,777,215 |
INT |
4 | -2147483648 |
0 |
2147483647 |
4,294,967,295 |
BIGINT |
8 | -263 |
0 |
263-1 |
264-1 |
所以我们在存储一个非负值时,推荐使用 UNSIGNED 参数,配置为符号,可获取正向多1倍的范围哦~
注意:INT有符号时最大的存储范围 2147483647 如果用于存放时间戳,即换算成时间:2038-01-19 11:14:07
浮点数,我使用得比较少,暂时就不写在这里了,等后期研究再补充~
2、字符串:
char 固定长度字符串:
CHAR和VARCHAR类型相似,但存储和检索方式不同。它们在最大长度和是否保留尾随空间方面也有所不同。CHAR和VARCHAR类型的声明长度表示您要存储的最大字符数。例如,CHAR(30)最多可以容纳30个字符。
CHAR列的长度固定为创建表时声明的长度。长度为0 ~ 255之间的任意值。在存储CHAR值时,将它们右填充为指定长度的空格。当检索CHAR值时,除非启用PAD_CHAR_TO_FULL_LENGTH SQL模式,否则将删除尾随空格。
| 存储内容 | CHAR(4) |
存储大小 | VARCHAR(4) |
存储大小 |
|---|---|---|---|---|
'' |
' ' |
4字节 | '' |
1字节 |
'ab' |
'ab ' |
4字节 | 'ab' |
3字节 |
'abcd' |
'abcd' |
4字节 | 'abcd' |
5字节 |
'abcdefgh' |
'abcd' |
4字节 | 'abcd' |
5字节 |
从上面的表中可以看到,char设置为4时,就算存一个空字符,也必需占用4个位置,而varchar是灵活存储,可以根据自己需求设置。
char适合存储用户密码的MD5哈希值,UUID,IP等,它的长度总是一样的。对于经常改变的值,char也好于varchar,因为固定长度的行不容易产生碎片,对于很短的列,char的效率也高于varchar。char(1)字符串对于单字节字符集只会占用一个字节,但是varchar(1)则会占用2个字节,因为1个字节用来存储长度信息。
varchar 可变字符串
长度可以指定为0到65,535的值,但varchar的真实索引范围0~255,超过了将不能增加索引。
实际上根据官方文档介绍:255~500将转换为tinytext存储,500~ 20000 为text存储,大于20000为mediumtext,所以大多情况下,varchar与text区别不大,但当字符小于255时,varchar可以使用索引,性能强于 text。所以我们认为当超过255的长度之后,使用varchar和text没有本质区别,只需要考虑一下两个类型的特性即可。
注意,上面说的是默认使用utf8(3字节的存储方式下) 768 / 3 = 256,使用InnoDB引擎时长度大于或等于768字节的固定长度字段编码为可变长度字段,可以存储在页面外(不索引)。
例如:我通常喜欢使用utf8mb4编码,每个字符占用4个字节存储数据。所以这时的varchar的有效索引范围为 768/4 = 192(并不是上面的255)。
| 字段类型 | 长度(utf8mb4) | 说明 |
| 以name结尾 | 64 | 如用户名、文件名等 |
| 以urlslug等路径 | 128 | 网址、路径等 |
| 存储简介的 description 、note等 | 180(也可以设置为191) | 短语、描述等 |
超过了191时,推荐使用下面的text的范围。
3、text 文本
如果把字符串当成一段文字的话,那么我们可以将text文本理解为一篇文章,当然文章有长短,所有mysql贴心的为我们准备了多个文本存储类型:
| 文本类型 | 存储范围 |
|---|---|
| TINYTEXT | 2^8 - 1 = 255 字节,utf8mb4约可存 63个字 |
| TEXT | 2^16 - 1 = 65535,utf8mb4约可存 16,383个字 |
| MEDIUMTEXT | 2^24 - 1 = 16777215 ,utf8mb4约可存 4,194,303个字 |
| LONGTEXT | 2^32 - 1 = 约4GB的文本内容哇~ |
通常情况下,我们使用text即可满足存储需要。
7、时间类
表示时间值的日期和时间数据类型是DATE、TIME、DATETIME、TIMESTAMP和YEAR。每个时间类型都有一系列有效值,以及一个“零”值,当您指定MySQL无法表示的无效值时可以使用。TIMESTAMP和DATETIME类型具有特殊的自动更新行为。
| 数据类型 | “零”值 |
|---|---|
| DATE | '0000-00-00' |
| TIME | '00:00:00' |
| DATETIME | '0000-00-00 00:00:00' |
| TIMESTAMP | '0000-00-00 00:00:00' |
| YEAR | 0000 |
datetime与timestamp有什么不同?
相同点:TIMESTAMP列的显示格式与DATETIME列相同。显示宽度固定在19字符,并且格式为YYYY-MM-DD HH:MM:SS。
不同点1:TIMESTAMP 使用4个字节储存,时间范围:1970-01-01 08:00:01 ~ 2038-01-19 11:14:07 值以UTC格式保存,涉及时区转化 ,存储时对当前的时区进行转换,检索时再转换回当前的时区。
不同点2:datetime 使用8个字节储存,时间范围:1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 实际格式储存,与时区无关。
如何使用TIMESTAMP的自动赋值属性?
将当前时间作为ts的默认值:ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP。
当行更新时,更新ts的值:ts TIMESTAMP DEFAULT ON UPDATE CURRENT_TIMESTAMP。
可以将1和2结合起来:ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP。
8、其它类
| 类型 | 存储范围 |
|---|---|
| JSON | 会自动验证json数据,并针对性能优化,所需的空间与LONGBLOB或LONGTEXT大致相同(约4GB) |
| BOLB | BLOB是一个二进制大对象,可以容纳可变数量的数据(同text)。四种BLOB类型是TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。 |
| 空间 | 专业地理环境存储,本人未接触过。 |
三、常用命令
1、查询
结果分组(按 GROUP BY 后面的字段分组)
SELECT `字段` FROM `表名` GROUP BY `字段`排序(按ORDER BY 后面的字段排序)
SELECT `字段` FROM `表名` ORDER BY `字段` DESC;限制返回长度
SELECT `字段` FROM `表旬` LIMIT 1;#返回1行数据SELECT `字段` FROM `表旬` LIMIT 2,1;#从第2行开始返回1行数据SELECT `字段` FROM `表旬` LIMIT 1 OFFSET 2;#同上,从第2行开始返回1行数据2、插入
将字段与值对应插入:
INSERT INTO `表名`(`字段1`,`字段12`) VALUES ('插入值字段1','插入值字段2')3、更新(修改)
UPDATE `表名` SET `字段1`='值1',`字段2`='值' WHERE 条件注:不使用WHERE限制条件将修改当前表里所有的值。
替换表里的数据:
UPDATE `表名` SET `字段`= REPLACE('查找内容','替换内容',`字段`) WHERE 条件例如,将文章表里的内容字段里“张三替换成”李四“:
UPDATE `articles_contents` SET `content`= REPLACE('张三','李四',`content`) WHERE `id`=1注:不使用WHERE限制将替换所有字段里的内容
4、删除表数据
DELETE FROM `表名` WHERE 条件注:不使用WHERE限制条件将删除当前表里所有的数据,保留当前自增ID。
如果要快速清空表并重置自增ID请使用下面的命名:
TRUNCATE `表名`5、 其它不常用命名
CREATE DATABASE 数据库名;#创建一个数据库USE 数据库名;#打开一个数据库drop database 数据库名;#删除一个数据库CREATE TABLE 表名 (`字段1` 存储数据类型);#创建一个表
CREATE TABLE `缓存表` (
`key` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`value` mediumtext COLLATE utf8mb4_general_ci NOT NULL COMMENT '字段的注释内容',
`expiration` int NOT NULL,
PRIMARY KEY (`key`) USING BTREE COMMENT '索引注释'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;DROP TABLE 数据表名;#删除一个数据表四、MySQL优化技巧
我们优化的目的主要是为了提升效率,减少资源使用、CPU和I/O操作,您必须将其最小化并尽可能提高效率。大部分情况下,我们通常通过下列几种方式来实现数据库优化:
- 避免全表扫描(命名索引)
- 定期使用 ANALYZE TABLE 语句来更新表统计信息(分析表)
- 每次查询尽量命中”索引“
- 选择查询的字段(SELECT 字段 FROM 表)
- 了解每个引擎查询调优化(如InnoDB和MyISAM优化方式不一样)。
- 配置my.conf 调整MySQL用于缓存的内存区域的大小和属性。
- 为查询、排序等字段创建索引,或者组合索引(SHOW INDEX FROM `表名`)。
- 使用 EXPLAIN 检查索引命中情况,请针对性优化(EXPLAIN SELECT * FROM `表名`)
- 数据库里只存文件路径,而不是文件本身的二进制。
- 对于大表或包含大量重复文本或数字数据的表格,请考虑使用COMPRESSED行格式。
- 如果索引列不能包含任何NULL值,请在创建表时将其声明为NOT NULL。
- 不要为每列创建单独的辅助索引,因为每个查询只能使用一个索引。
- 不要在主键中指定太多或太长的列,因为这些列值在每个辅助索引中重复。
- 优化MySQL的磁盘I/O。
五、实用技巧
1、数据库常识
- 能用int的就不用char或者varchar。
- 能用tinyint的就不用int。
- 使用UNSIGNED存储非负数值。
- 不建议使用ENUM、SET类型,使用TINYINT来代替。
- 使用短数据类型,比如取值范围为0-80时,使用TINYINT UNSIGNED。
- 存储精确浮点数必须使用DECIMAL替代FLOAT和DOUBLE。
除非注明,网络人的文章均为原创,转载请以链接形式标明本文地址:https://www.55mx.com/post/222

本站推荐阅读






热门点击文章
- 【Laravel经验】强大的Model应该这样用阅读:515 评论:0
- 各大门户网站网页变灰的代码阅读:514 评论:0
- 在城市体面的“流浪”指北阅读:493 评论:0
- 利用程序计算小学3年级的奥数题 2,4,5,7,11,13,23,25,( ),( )阅读:457 评论:0
- mysql 14001错误 could not start the service mysql阅读:437 评论:0
- 【Laravel实战】Ajax验证captcha 验证码阅读:435 评论:0
- 家庭云(NAS)最简单的组建技术阅读:424 评论:1
- 测试阿里云服务器的1M带宽能支持多少人在线阅读:418 评论:0
- “无奸不商”的原来意思“无尖不商”,可现实却是“无贱不商”阅读:418 评论:0
- 通过指令3秒查出你的男(女)朋友用手机在做什么阅读:418 评论:0
- 一个可以防止图片木马的PHP上传类阅读:418 评论:0
- 通过Kcptun给Shadowsocks加速,能跑满你的带宽阅读:418 评论:0
- PHP中实用的常量和系统全局变量阅读:417 评论:0
- 让你的网站每天更新快照并实时收录并不难!阅读:416 评论:0
- 一个比较好用的JS原生封装Ajax.js,使用方法与jQuery一样阅读:404 评论:0
《【MySQL实战】数据库常用知识点/技术收录(不断更新中)》的网友评论(0)