GO语言学习实战2:创建各种链表并对其增加、删除、排序最后实现约瑟夫问题抽奖
GO语言是区块链开发的主要语言,在学习区块链之前需要搞清楚链表是怎么相互关联的,链表是一种有序且结构相同的数据列表,也是一种算法下的数据结构。
根据项目要求我们需要使用到不同的链表算法,单向链表、双向链表、环形链表等。
一.单链表基本概念
单链表是一种顺序存储的结构。 有一个头节点(空),没有值域,只有链域(与下一个数据连接),专门存放第一个节点的地址。 有一个尾节点,有值域,也有链域,链域值始终为NULL(判断最后一个可以使用链域==nil)。
每个节点(结构体)必须包含至少两部分:数据域(值域)+指针域(链域),上一个节点的指针指向下一结点,依次相连,形成链表。
//ClassNode 学生学号结构体
type ClassNode struct {
/* 数据域(值域)开始 */
No int
Name string
Sex bool
/* 数据域(值域)结束 */
LinkNext *ClassNode //指针域(链域),用于连接到下一组数据
}
func main() {
LinkHead := &ClassNode{} //定义一个空结构做为链表的头部
student := &ClassNode{
No: 1,
Name: "张三",
Sex: true,
}
LinkHead.LinkNext = student //将头节点与第一组数据连接
student.LinkNext = &ClassNode{ //链接下一组数据
No: 2,
Name: "李四",
Sex: true,
}
student.LinkNext.LinkNext = &ClassNode{ //又链接一组数据
No: 3,
Name: "王翠花",
Sex: false,
}
//遍历单链表
temp := LinkHead //从链表的头部分开始接收
for {
if temp.LinkNext == nil {
break
}
fmt.Println(temp.LinkNext) //打印链表的数据结构
temp = temp.LinkNext //指向下一组数据
}
}
/*
&{1 张三 true 0xc0000b6360}
&{2 李四 true 0xc0000b6390}
&{3 王翠花 false }
*/
特别注意的是每个链表必须包含头结点(数据域一般无意义或者为空,有时用来存储链表长度等等)
所以,在单链表中为找第i个节点或数据元素,必须先找到第i - 1 节点或数据元素,而且必须知道头节点(LinkHead),否者整个链表无法访问。
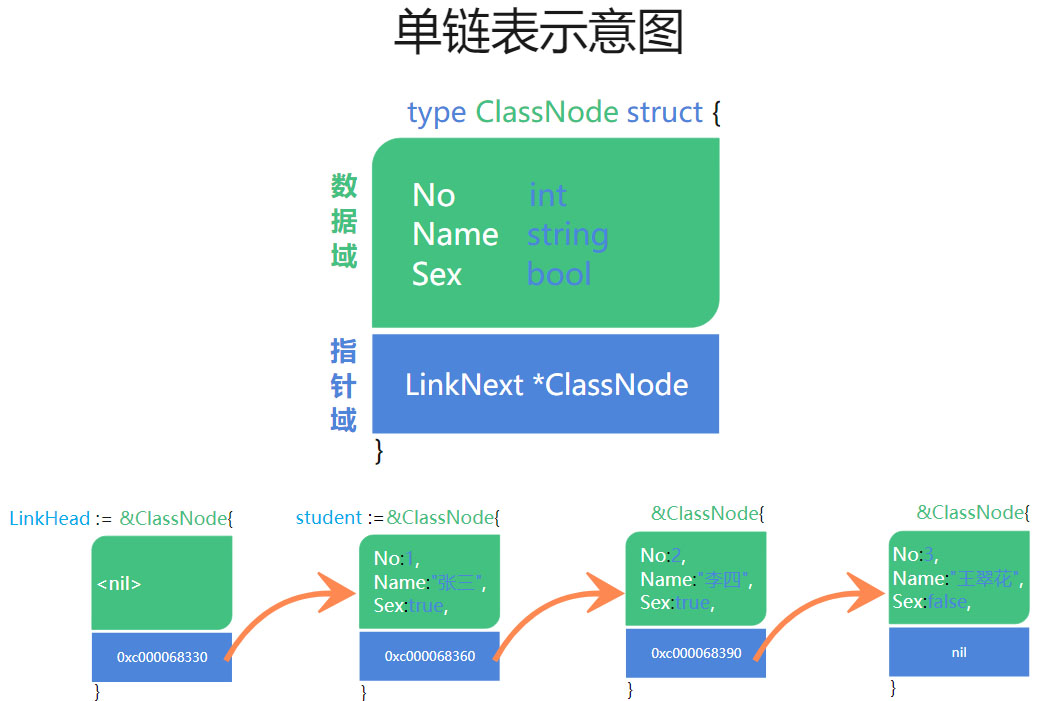
二、单向链表的示意图
结合上面的代码通过内存中的存储示意图加深理解:
三、对单向链表增、删、排序、查(遍历)封装成函数:
/* 数据结构接上面代码 */
//AppendLinkNode (head=头部,node=要追加的数据)在尾部追加一组数据的链接
func AppendLinkNode(head *ClassNode, node *ClassNode) {
temp := head //定义一个辅助的临时节点指向链表头
for {
if temp.LinkNext == nil { //上面示意图里可以看到最后一个linkNext为nil
temp.LinkNext = node //在节点的最后面增加一个节点
return //完成了链接退出
}
temp = temp.LinkNext //让temp不断的指向下一个结点
}
}
//OrderLinkNode 对链表排序
func OrderLinkNode(head *ClassNode) {
if head.LinkNext == nil {
return //空链表退出
}
NodeLen := head.LinkNext //外圈循环用于计算链表数量
for {
if NodeLen.LinkNext == nil {
break //已到链表尾部
}
temp := head.LinkNext //内圈循环用于对比排序
for {
if temp.LinkNext == nil {
break //已到链表尾部
} else if temp.No > temp.LinkNext.No {
//如果No值大于的情况就进行值交换
temp.No, temp.LinkNext.No = temp.LinkNext.No, temp.No
temp.Name, temp.LinkNext.Name = temp.LinkNext.Name, temp.Name
temp.Sex, temp.LinkNext.Sex = temp.LinkNext.Sex, temp.Sex
//只能对“数据域”里面的值交换,目前还没有找到指针域(链域)交换的解决办法
}
temp = temp.LinkNext //对比下一组
}
NodeLen = NodeLen.LinkNext //进行下一次的内圈循环对比
}
}
//OrderInsertNode 按head.No顺序插入到链表
func OrderInsertNode(head *ClassNode, NewNode *ClassNode) {
temp := head //定义一个辅助的临时节点指向链表头
var flag bool //标记重复节点
for {
if temp.LinkNext == nil {
break //已到链表尾部,将会插入到尾部
} else if NewNode.No < temp.LinkNext.No {
break //NewNode小于temp.LinkNext则会插入到这个位置,倒序改为>
} else if NewNode.No == temp.LinkNext.No {
flag = true
break
}
temp = temp.LinkNext //指向下一组数据
}
if flag {
fmt.Println("NewNode.No=", NewNode.No, "已存在,无法增加")
} else {
NewNode.LinkNext, temp.LinkNext = temp.LinkNext, NewNode //插入到节点位置
}
}
//DelLinkNode 删除一个head.No==id的节点
func DelLinkNode(head *ClassNode, id int) {
temp := head //定义一个辅助的临时节点指向链表头
var flag bool //定义一个是否找到的标志
for {
if temp.LinkNext == nil {
break //已到链表尾部,退出查找
} else if temp.LinkNext.No == id {
flag = true //找到了No=id的节点
break
}
temp = temp.LinkNext //继续查找下一组数据
}
if flag {
temp.LinkNext = temp.LinkNext.LinkNext
/*
上面对比的是temp.LinkNext.No==id,所以要删除的是temp.LinkNext
我们只需要把temp.LinkNext的值替换成下一组数据就实现了No=id的删除
如果temp.LinkNext.LinkNext 没有值,系统默认值为nil也等同于删除
*/
} else {
fmt.Println("没有找到No=", id, "的数据")
}
}
//PrintLinkNode (head=头部) 遍历并打印链表数据
func PrintLinkNode(head *ClassNode) {
temp := head //定义一个辅助的临时节点
for {
if temp.LinkNext == nil {
break //到最后的节点就退出,如果是空链表将直接退出无提示
}
fmt.Println(*temp.LinkNext) //打印链表的数据结构
temp = temp.LinkNext //指向下一组数据
}
}
func main() {
LinkHead := &ClassNode{} //定义一个空结构做为链表的头部
/* 使用OrderInsertNode按No从小到大插入 */
OrderInsertNode(LinkHead, &ClassNode{No: 5, Name: "王八", Sex: true})
OrderInsertNode(LinkHead, &ClassNode{No: 1, Name: "张三", Sex: true})
OrderInsertNode(LinkHead, &ClassNode{No: 4, Name: "赵六妹", Sex: false})
OrderInsertNode(LinkHead, &ClassNode{No: 2, Name: "李四", Sex: true})
/* 使用OrderInsertNode增加一个No重复值 */
OrderInsertNode(LinkHead, &ClassNode{No: 2, Name: "李四的妹妹", Sex: false})
/* NewNode.No= 2 已存在,无法增加 */
/* 下面使用AppendLinkNode追加到链表的尾部 */
AppendLinkNode(LinkHead, &ClassNode{No: 3, Name: "王翠花", Sex: false})
PrintLinkNode(LinkHead) //遍历并打印链表数据
/*
{1 张三 true 0xc0000683c0}
{2 李四 true 0xc000068390}
{4 赵六妹 false 0xc000068330}
{5 王八 true 0xc0000683f0}
{3 王翠花 false }
*/
OrderLinkNode(LinkHead) //对链表排序
fmt.Println("========================> 对链表排序后 <===================")
PrintLinkNode(LinkHead)
/*
{1 张三 true 0xc0000683c0}
{2 李四 true 0xc000068390}
{3 王翠花 false 0xc000068330}
{4 赵六妹 false 0xc0000683f0}
{5 王八 true }
*/
DelLinkNode(LinkHead, 5) //删除No=5的数据
fmt.Println("=====================> 删除No=5的数据后< ==================")
PrintLinkNode(LinkHead)
/*
{1 张三 true 0xc0000683c0}
{2 李四 true 0xc000068390}
{3 王翠花 false 0xc000068330}
{4 赵六妹 false }
*/
fmt.Println("====================> 只保留No=1的数据后 < ================")
DelLinkNode(LinkHead, 4)
DelLinkNode(LinkHead, 3)
DelLinkNode(LinkHead, 2)
PrintLinkNode(LinkHead)
/* {1 张三 true } */
fmt.Println("====================> 删除一个不存在的数据 < ==============")
DelLinkNode(LinkHead, 99)
/* 没有找到No= 99 的数据 */
fmt.Println("=======================> 删除全部数据后 <==================")
DelLinkNode(LinkHead, 1)
PrintLinkNode(LinkHead)
}单向链表缺点:只能朝一个方向查找,不能自我删除,只能依靠辅助节点temp的LinkNext来删除。
四、双向链表
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接指向前一组数据(LinkPrev)和后一组数据(LinkNext)。
所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱节点(LinkPrev)和后继节点(LinkNext)。
双向链表可以自我删除,也可以向前或者向后查找。
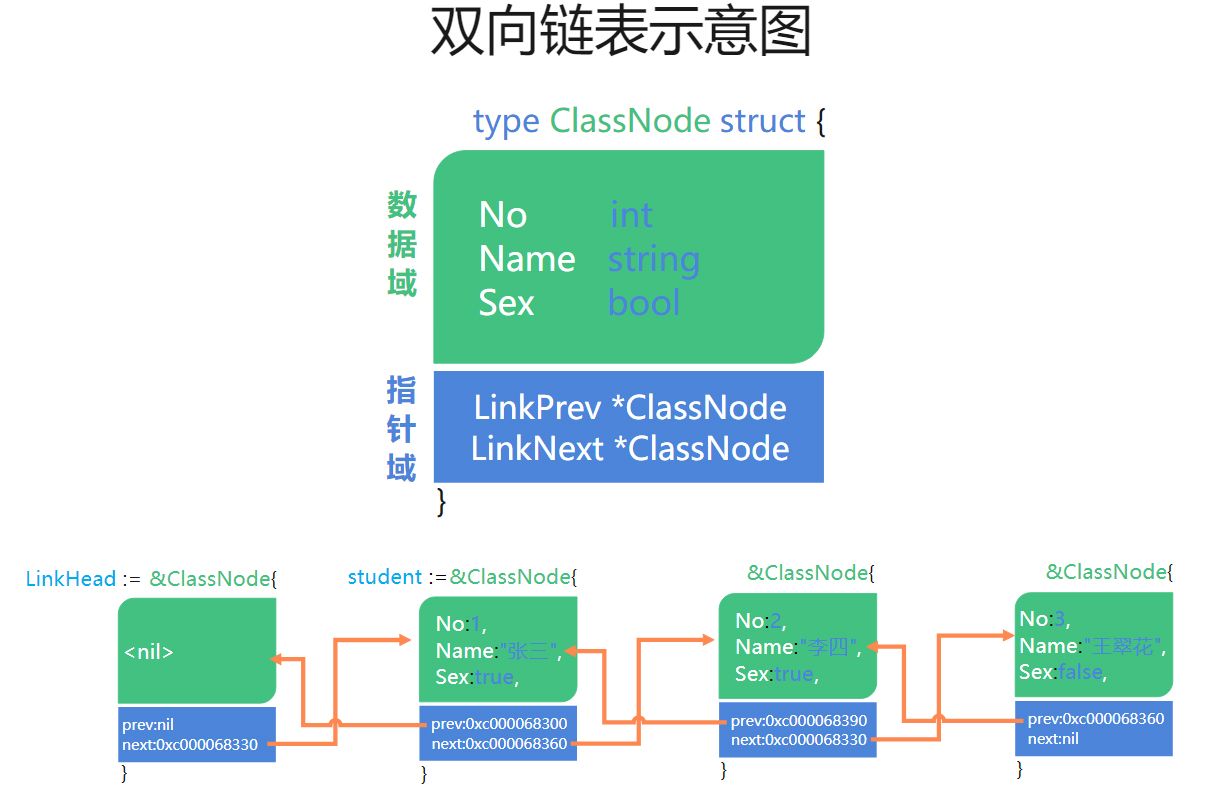
五、双向链表追加、任意位置追加、删除、倒序打印等操作:
与上面单向链表相比,双向链表只增加了一个指向上一个节点的新指针(LinkPrev),我们只对上面代码做一些点小修改即可实现对双向链表的管理操作。
package main
import "fmt"
//ClassNode 学生学号结构体
type ClassNode struct {
/* 数据域(值域)开始 */
No int
Name string
Sex bool
/* 数据域(值域)结束 */
LinkPrev *ClassNode //指针域(链域),用于链接到上一组数据
LinkNext *ClassNode //指针域(链域),用于连接到下一组数据
}
//AppendTwoWayNode 链表尾部追加一个双向节点
func AppendTwoWayNode(head *ClassNode, node *ClassNode) {
temp := head //定义一个辅助的临时节点指向链表头
for {
if temp.LinkNext == nil { //上面示意图里可以看到最后一个linkNext为nil
break //找到最后的节点退出循环
}
temp = temp.LinkNext //让temp不断的指向下一个结点
}
temp.LinkNext = node //在节点的最后面追加一个节点
node.LinkPrev = temp //新节点与上一个节点链接。与单向相比增加的部分
}
//InsertNode 找到No=id的数据并在前面插入一个newNode双向节点
func InsertNode(head *ClassNode, id int, newNode *ClassNode) {
temp := head //定义一个辅助的临时节点指向链表头
for {
if temp.LinkNext == nil {
AppendTwoWayNode(head, newNode) //未找到No=id的节点,加到链表尾部
return
} else if temp.LinkNext.No == id { //找到用户No=id的数组
newNode.LinkNext = temp.LinkNext //新节点链接到当前节点的下一组
newNode.LinkPrev = temp //新节点的上一组链接到当前节点
if temp.LinkNext != nil {
temp.LinkNext.LinkPrev = newNode //确定现在的节点不是最后节点
}
temp.LinkNext = newNode //当前节点与新节点链接
break //完成任务
}
temp = temp.LinkNext //让temp不断的指向下一个结点
}
}
//DelTwoWayNode 删除一个No=id的双向节点
func DelTwoWayNode(head *ClassNode, id int) {
temp := head //定义一个辅助的临时节点指向链表头
for {
if temp.LinkNext == nil {
return
} else if temp.LinkNext.No == id { //找到用户No=id的数组
temp.LinkNext = temp.LinkNext.LinkNext //当前节点的指针域指向新位置
if temp.LinkNext != nil {
temp.LinkPrev = temp //确定现在的节点不是最后节点
}
break //完成任务
}
temp = temp.LinkNext //让temp不断的指向下一个结点
}
}
//PrintLinkNode 倒序打印链表
func reversePrint(head *ClassNode) {
if head.LinkNext == nil {
return //空链表
}
temp := head //辅助节点保护数据
for {
if temp.LinkNext == nil {
break //找到最后的节点
}
temp = temp.LinkNext
}
for {
if temp.LinkPrev == nil {
break //到最前的节点就退出
}
fmt.Println(*temp) //与单向不同的地方,直接打印当前即可
temp = temp.LinkPrev //指向上一组数据
}
}
//PrintLinkNode (head=头部) 遍历并打印链表数据
func PrintLinkNode(head *ClassNode) {
temp := head //辅助的临时节点作用是为了不破坏原有数据
for {
if temp.LinkNext == nil {
break //到最后的节点就退出,如果是空链表将直接退出无提示
}
fmt.Println(*temp.LinkNext) //打印链表的数据结构
temp = temp.LinkNext //指向下一组数据
}
}
func main() {
LinkHead := &ClassNode{} //定义一个空结构做为链表的头部
AppendTwoWayNode(LinkHead, &ClassNode{No: 5, Name: "王八", Sex: true})
AppendTwoWayNode(LinkHead, &ClassNode{No: 1, Name: "张三", Sex: true})
AppendTwoWayNode(LinkHead, &ClassNode{No: 4, Name: "赵六妹", Sex: false})
AppendTwoWayNode(LinkHead, &ClassNode{No: 2, Name: "李四", Sex: true})
reversePrint(LinkHead) //倒序打印双向链表
/*
{2 李四 true 0xc0000683c0 }
{4 赵六妹 false 0xc000068390 0xc0000683f0}
{1 张三 true 0xc000068360 0xc0000683c0}
{5 王八 true 0xc000068330 0xc000068390}
*/
fmt.Println("=================> 在4号前面插入数据结果 <=================")
InsertNode(LinkHead, 4, &ClassNode{No: 3, Name: "李三妹", Sex: false}) //在ID4后插入:“李三妹”
PrintLinkNode(LinkHead) //顺序打印双向链表
/*
{5 王八 true 0xc000068330 0xc000068390}
{1 张三 true 0xc000068360 0xc0000684e0}
{3 李三妹 false 0xc000068390 0xc0000683c0}
{4 赵六妹 false 0xc0000684e0 0xc0000683f0}
{2 李四 true 0xc0000683c0 }
*/
fmt.Println("=================> 删除5号数据后的结果 <=================")
DelTwoWayNode(LinkHead, 5) //删除一个LinkHead.No=5的双向节点
PrintLinkNode(LinkHead)
/*
{1 张三 true 0xc000068360 0xc0000684e0}
{3 李三妹 false 0xc000068390 0xc0000683c0}
{4 赵六妹 false 0xc0000684e0 0xc0000683f0}
{2 李四 true 0xc0000683c0 }
*/
}六、单向环形链表
单向环形链表是在单向链表的基础把单向链表的尾部.LinkNext=nil链接上头部LinkHead即可,通俗讲就是把尾节点的下一跳指向头结点。所以我们要判断链表是否到达尾部,只需要使用辅助节点的尾部.LinkNext==LinkHead。
在单向链表中,头指针(LinkHead)是相当重要的,因为单向链表的操作都需要头指针,所以如果头指针丢失或者破坏,那么整个链表都会遗失,并且浪费链表内存空间,因此我们引入了单向循环链表这种数据结构。
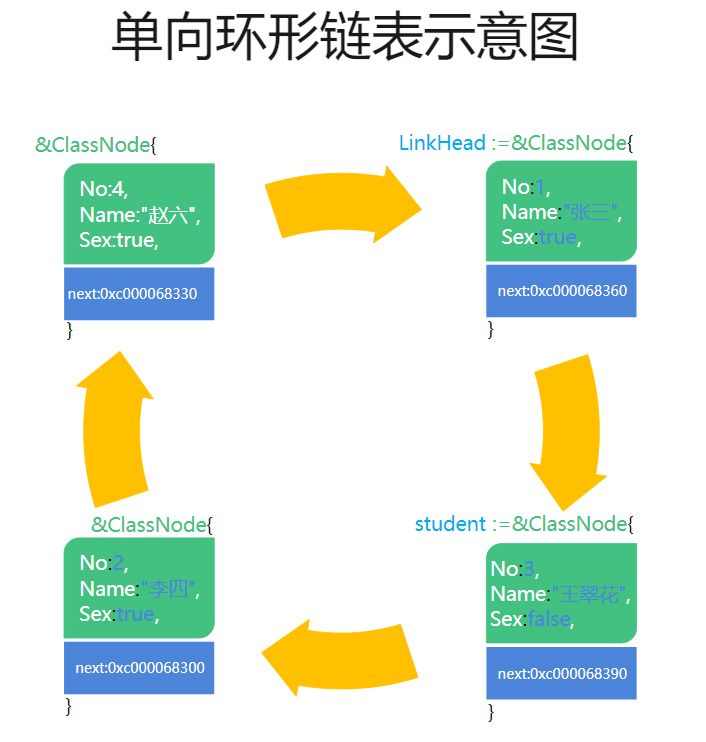
单向循环链表的插入与单向链表有所不同,因为单向循环链表首尾相连,所以没有从尾部插入的问题。
(1)从链表头部插入
将新插入的节点变为链表头部,next指向原来的第一个节点,在遍历整个链表找到链表末尾(即它的next指向的是head的那个节点),将这个节点的next指向新插入的节点,最后再将链表头指针指向新节点。
(2)从链表中间插入
此时插入的过程和单向链表的一样,找到要插入位置前驱节点,将前驱节点的next指向新节点的next,再将前驱节点的next指向新插入的节点。
package main
import (
"fmt"
"time"
)
//NumberNode 一组数字的链表结构
type NumberNode struct {
No int
Next *NumberNode //下一组数据链域
}
//delNode 删除head链表里值=id的数据
func delNode(head *NumberNode, id int) *NumberNode {
if head.Next == nil {
return head //空链表
}
//只有1个结点
if head.Next == head && head.No == id {
head.Next = nil //取消链接
return head
}
//下面是多个节点的删除操作
tempStart := head //辅助变量 指向链表头
tempPrev := head //辅助节点 将指向链表的结尾也就是tempStart的上一条数据
for {
if tempPrev.Next == head {
break //找到了链表的尾部就退出
}
tempPrev = tempPrev.Next //将指向链表的最后
}
/*
thisNode := head,这时候thisNode指向了链表头,for后helper指向链表尾
可以理解为helper=thisNode-1或者 helper是thisNode前一条数据
*/
for {
if tempStart.No == id {
if tempStart == head {
head = head.Next //如果删除的是头结点,需要指向下一个结点,否则头结点会丢失
}
if tempPrev.Next == tempStart && tempPrev.Next.No == id && tempStart.No == id {
fmt.Println("id=", id, "这里tempPrev.Next与tempStart都是指向的将被删除的数据:tempStart=", tempStart)
}
tempPrev.Next = tempStart.Next
fmt.Println(id, "删除成功")
break //完成并退出
}
if tempStart.Next == head {
fmt.Println("已到链表尾部了并未找到要删除的数据")
break //退出查找
}
tempStart = tempStart.Next //进行下一次查找
tempPrev = tempPrev.Next //同时移动指针
}
return head
}
func main() {
LinkHead := &NumberNode{} //链表的头部
temp := LinkHead
for i := 1; i <= 10; i++ {
number := &NumberNode{No: i}
if i == 1 {
LinkHead = number
temp = number
temp.Next = LinkHead
} else {
/* 这里可以将temp与temp.Next理解成2个不同的变量 */
temp.Next = number //向链表里追加新数据到尾部
temp = number //将temp.Next追加的新数据重新指向temp
temp.Next = LinkHead //将首尾相联
}
}
//下面可以无限遍历单向环形链表,死循环
LinkHead = delNode(LinkHead, 2) //删除ID=2的数据
LinkHead = delNode(LinkHead, 1) //删除链表头
LinkHead = delNode(LinkHead, 10) //删除链表尾
//删除后结果需要返回给LinkHead,具体原因还未知
temp = LinkHead
for {
fmt.Println(*temp)
time.Sleep(time.Second / 4)
temp = temp.Next
if temp == LinkHead {
break //如果循环未退出说明 delNode函数有错,导致了链表头信息丢失
}
}
/*
{3 0xc000034230}
{4 0xc000034240}
{5 0xc000034250}
{6 0xc000034260}
{7 0xc000034270}
{8 0xc000034280}
{9 0xc000034220}
*/
}
七、解决约瑟夫问题并抽奖
约瑟夫问题(有时也称为约瑟夫斯置换,是一个计算机科学和数学中的问题。在计算机编程的算法中,类似问题又称为约瑟夫环。又称“丢手绢问题”)
约瑟夫问题是个有名的问题:N个人围成一圈,从第一个开始报数,第M个将被杀掉,最后剩下一个,其余人都将被杀掉。例如N=6,M=5,被杀掉的顺序是:5,4,6,2,3。
分析:
(1)由于对于每个人只有死和活两种状态,因此可以用布尔型数组标记每个人的状态,可用true表示死,false表示活。
(2)开始时每个人都是活的,所以数组初值全部赋为false。
(3)模拟杀人过程,直到所有人都被杀死为止。
上面来源百度百科:https://baike.baidu.com/item/%E7%BA%A6%E7%91%9F%E5%A4%AB%E9%97%AE%E9%A2%98
当然我们不是为了Kill而写代码,我们要的是最后留下的那个人成为唯一中奖的幸运儿。
下面我们使用一个单向的环形链表来实用即可:
package main
import (
"fmt"
"math/rand"
"time"
)
type Users struct {
No int //用户ID
Name string //用户名
Next *Users //指针域(链域)
}
//LinkUser 将数组切片用户转换为循环链表并返回链表头指针值
func LinkUser(Name []string) *Users {
first := &Users{} //定义一个链表头的空结点
ptrNext := &Users{} //定义一个移动的指针空结点
if len(Name) < 1 {
fmt.Println("抽奖的人数太少~")
return first
}
//for range循环的构建这个环形链表,并让首尾链接
for i, v := range Name {
user := &Users{
No: i, //数组索引是从0开始的
Name: v, //用户名
}
if i == 0 {
first = user //第1个用户first做为链表头将与最后的ptrNext链接
ptrNext = user //将指针指向第1个用户
ptrNext.Next = first //ptrNext.Next指向first构造单用户的环形链表
} else {
ptrNext.Next = user //追加一个用户到链表
ptrNext = user //移动指针
ptrNext.Next = first //头尾相接形成多用户的环形链表
}
}
return first //返回链表头
}
//ShowUsers 显示所有用户ID
func ShowUsers(first *Users) {
//处理一下如果环形链表为空
if first.Next == nil {
fmt.Println("链表为空,没有用户...")
return
}
ptrNext := first //创建一个指针,帮助遍历.[说明至少有一个用户]
for {
fmt.Printf("%s 编号:%d t", ptrNext.Name, ptrNext.No)
//退出的条件?curBoy.Next == first
if ptrNext.Next == first {
break
}
//curBoy移动到下一个
ptrNext = ptrNext.Next
}
}
//PlayGame 指定一个随机开始的位置和一个每次要淘汰的位置
func PlayGame(first *Users, startNo int, countNum int) {
if first.Next == nil {
fmt.Println("空的链表,没有用户参与~")
return
}
tail := first //假设只有1个用户参与,让尾巴指向第1个用户
//尝试去找到最后的用户是哪个?非常重要~
for {
if tail.Next == first {
break //tail尾巴与头链接在一起了说明tail到了最后
}
tail = tail.Next //继续判断下一个是不是最后的用户
}
for i := 1; i <= startNo-1; i++ {
first = first.Next //让first 移动到 startNo
tail = tail.Next //让tail 也移动到 startNo
}
for {
//开始数countNum-1次
for i := 1; i <= countNum-1; i++ {
first = first.Next
tail = tail.Next
}
fmt.Printf("%d、%s 被淘汰了n", first.No, first.Name)
time.Sleep(time.Second / 3)
first = first.Next //从链表中删除这个用户
tail.Next = first //尾巴指向新位置
if tail == first {
break //判断如果 tail == first, 只有1个用户中奖了~
}
}
fmt.Printf("n===> 恭喜用户ID:%d 姓名:%s 中奖了~ <====n", first.No, first.Name)
}
func main() {
//匿名数组切片的好处是在给函数传值的时候可以不指定数组长度,追加新数据也比较方便~
NameSlice := []string{"陈大", "黄二", "张三", "李四", "王五", "赵六", "田七", "亢八", "周九", "吴十"} //定义一个匿名数组切片
userHead := LinkUser(NameSlice)
fmt.Println("===> 有请下面的用户参与本次的抽奖活动~ <====")
fmt.Println()
ShowUsers(userHead)
cuntUsers := len(NameSlice) //统计有多少个用户参与
i := 1
for {
userHead := LinkUser(NameSlice) //重新生成链表
fmt.Println()
fmt.Println("===> 第", i, "次抽奖开始呢~ <===")
rand.Seed(time.Now().UnixNano()) //纳秒级随机种子
PlayGame(userHead, rand.Intn(cuntUsers-1), rand.Intn(i))
time.Sleep(time.Second * 2)
if i >= cuntUsers {
break //抽奖cuntUsers次后退出
}
i++
}
fmt.Println("抽奖已结束,请按回车[ENTER]键退出程序~")
fmt.Scanln()
}上面代码是通过一个首尾相联的环形链表完成的,每次运行中奖结果都会不一样的哦~。
===> 有请下面的用户参与本次的抽奖活动~ <===
黄二 编号:1 张三 编号:2 李四 编号:3 王五 编号:4 赵六 编号:5 田七 编号:6 亢八 编号:7 周九 编号:8 吴十 编号:9
3、李四 被淘汰了
7、亢八 被淘汰了
2、张三 被淘汰了
8、周九 被淘汰了
5、赵六 被淘汰了
4、王五 被淘汰了
6、田七 被淘汰了
1、黄二 被淘汰了
===> 恭喜用户ID:9 姓名:吴十 中奖了~ <===
除非注明,网络人的文章均为原创,转载请以链接形式标明本文地址:https://www.55mx.com/post/89

本站推荐阅读






热门点击文章
- 【Laravel经验】强大的Model应该这样用阅读:515 评论:0
- 各大门户网站网页变灰的代码阅读:514 评论:0
- 在城市体面的“流浪”指北阅读:493 评论:0
- 利用程序计算小学3年级的奥数题 2,4,5,7,11,13,23,25,( ),( )阅读:457 评论:0
- mysql 14001错误 could not start the service mysql阅读:437 评论:0
- 【Laravel实战】Ajax验证captcha 验证码阅读:435 评论:0
- 家庭云(NAS)最简单的组建技术阅读:424 评论:1
- 测试阿里云服务器的1M带宽能支持多少人在线阅读:418 评论:0
- “无奸不商”的原来意思“无尖不商”,可现实却是“无贱不商”阅读:418 评论:0
- 通过指令3秒查出你的男(女)朋友用手机在做什么阅读:418 评论:0
- 一个可以防止图片木马的PHP上传类阅读:418 评论:0
- 通过Kcptun给Shadowsocks加速,能跑满你的带宽阅读:418 评论:0
- PHP中实用的常量和系统全局变量阅读:417 评论:0
- 让你的网站每天更新快照并实时收录并不难!阅读:416 评论:0
- 一个比较好用的JS原生封装Ajax.js,使用方法与jQuery一样阅读:404 评论:0
《GO语言学习实战2:创建各种链表并对其增加、删除、排序最后实现约瑟夫问题抽奖》的网友评论(0)